from nikodindon@lemmy.world to selfhosted@lemmy.world on 20 Mar 07:47
https://lemmy.world/post/44513564
I just pushed v22 of my project : a local AI companion for Radarr, that goes beyond generic genre or TMDb lists.
This isn’t “yet another recommender”. It’s your personal taste explorer that actually gets the vibe you want in natural language and builds recommendations starting from your existing library.
Key highlights from a real recent run:
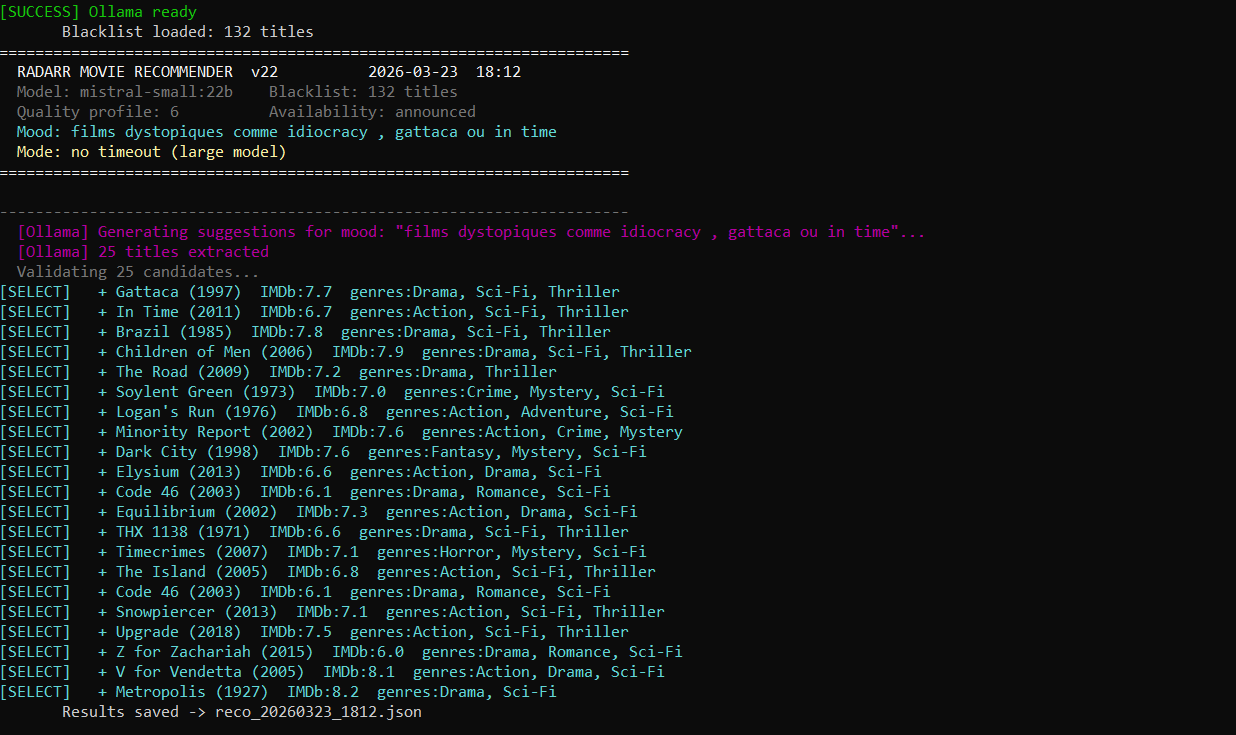
- Command:
–mood "dystopian films like Idiocracy, Gattaca or In Time" - Output: Metropolis (1927), V for Vendetta, Children of Men, Brazil (1985), Minority Report, Dark City, Equilibrium, Upgrade, The Road… → oppressive/surveillance/inequality/societal critique atmosphere, not just “dark sci-fi”.
How it works :
- Starts by sampling random movies from your Radarr collection (or uses your mood/like/saga input).
- Asks a local Ollama LLM (e.g. mistral-small:22b) for 25 thematic suggestions based on atmosphere/vibe.
- Validates each via OMDb (IMDb rating, genres, plot, director, cast…).
- Scores intelligently: IMDb rating + genre match + director/actor bonus + plot embedding similarity (cosine on Ollama embeddings).
- Adds the top ones directly to Radarr (with confirmation: all / one-by-one / no).
- Persistent blacklist to avoid repeats.
Different modes :
–mood “dark psychological thrillers with unreliable narrators”, any vibe you describe–like “Parasite” --mood “mind-bending class warfare”(or just–like “Whiplash”)–saga(auto-detects incomplete sagas in your library and suggests missing entries) or–saga “Star Wars”–director “Kubrick”/–actor “De Niro”/–cast “Pacino De Niro”(movies where they co-star)–analyze→ full library audit + gaps (e.g. “You’re missing Kurosawa classics and French New Wave”)–watchlist→ import from Letterboxd/IMDb–auto→ perfect for daily cron / Task Scheduler (wake up to 10 fresh additions)
Standout features:
- 100% local + privacy-first (Ollama + free OMDb API only)
- No cloud AI, no tracking
- colored console output, logs, stats, HTML/CSV exports
- Synopsis preview before adding
- Configurable quality profile, min IMDb, availability filters
- Works on Windows, Linux, Mac
GitHub (clean single-file Python script + detailed README):
github.com/nikodindon/radarr-movie-recommender
If you’re tired of generic Discover lists, Netflix-style randomness, or manual hunting give it a spin. The vibe/mood mode + auto saga completion really change how you expand your collection.
Let me know what you think, any weird mood examples you’d like to test, or features you’d want added!
threaded - newest
A recommendation for Moonrise Kingdom based on Mickey 17? The genres might match, but those are totally different movies.
Also, A Bug’s Life from Mickey 17!?
That made me lol so hard. Like what’s the fucking point of this thing when it comes up with shit like that?
Since no one is leaving critical comments that might explain all the downvotes, I’m going to assume they’re reflexively anti-AI, which frankly, is a position that I’m sympathetic to.
But one of the benign useful things I already use AI for, is giving it criterias for shows and asking it to generate lists.
So I think your project is pretty neat and well within the scope of actually useful things that AI models, especially local ones, can provide the users.
No LLM use is benign. The effects on the environment, the internet, and society are real, and that cannot be ignored.
You can make the argument that in some cases it is justified, e.g.: for scientific research.
So running a local model is unforgivable, but “scientific research” running on hyperscalers, can be justified?
chill, this is extracting text embeddings from a local model, not generating feature-length films
that’s like saying “no jet use is benign” meant for comparing a private jet to a jet-ski
the generative aspect is not even used here
Didn’t down vote you. I hear this line of complaint in conjunction with AI, especially if the person saying it is anti-AI. Without even calculating in AI, some 25 million metric tons of CO2 emissions annually from streaming and content consumption. Computers, smartphones, and tablets can emit around 200 million metric tons CO2 per year in electrical consumption. Take data centers for instance. If they are powered by fossil fuels, this can add about 100 million metric tons of CO2 emissions. Infrastructure contributes around 50 million metric tons of CO2 per year.
Now…who wants to turn off their servers and computers? Volunteers? While it is true that AI does contribute, we’re already pumping out some significant CO2 without it. Until we start switching to renewable energy globally, this will continue to climb with or without AI. It seems tho, that we will have to deplete the fossil fuel supply globally before renewables become the de facto standard.
Saw it was already commented about CO2, so I thought I'd counter-point your environment claim regarding water usage (since that is something I've seen a lot of too).
The ISSA had a call to action due to the AI water use "crisis": https://www.issa.com/industry-news/ai-data-center-water-consumption-is-creating-an-unprecedented-crisis-in-the-united-states/
68 billion gallons of water by 2028! That's a lot....right?
Well, what I found is that this is somewhat of a bad faith argument. 68 billion gallons annually is a lot for one town, but those are numbers from a national level and it isn't compared to usage from anything else.
So, lets look at US agriculture (that's something that's tracked very well by the USDA): https://www.nass.usda.gov/Publications/Highlights/2024/Census22_HL_Irrigation_4.pdf
That's 26.4 trillion gallons of water annually.
So, AI datacenter represents 0.26% of agriculture consumption.
If AI datacenter consumption is a crisis, why is agriculture consumption not a crisis?
You could argue that agriculture produces "something useful", but usefulness doesn't factor into the scarcity of a resource.
So, either its not a crisis, or you are cherry picking something that has no meaningful outcome to solving the problem.
yeah, I think the whole “water” argument really dilutes the case against data centers.
On a serious note, the argument works for areas that already struggle to supply enough water for consumers. Otherwise, we should be focusing more on the power stress to the grid, and the domino effect on supply chain of hardware cost increases that it’s happening across many industries. It started with GPUs, now it’s CPU, storage, networking equipment, and other components.
If these prices are too high for a couple of years, we’ll start seeing generalized price increases as companies need to pass along the costs to consumers.
I think the supply chain issue is probably the most pressing out of all of them. The other points people have are either non-issues or a result of dropping usage hogs into existing electrical infrastructure. Infrastructure can be updated, though.
Supply chain is different. There isn't a supply shortage of chips, its that profitability dictates you should sell them to datacenters or adjacent industry. Unlike infrastructure where you can just build out more, adding more supply for chips just means you have more to sell to datacenters. Since the demand is there, end of day profits will always win.
Do You drive a car? Eat meat? Fly for holidays?
Nothing is black and white.
Huh? There are other ways to link similarities of movies without the use of a llm. You may use ai to find similar movies but it’s nonsense that everyone has to ask a llm to link movies.
no one is saying everyone has to ask an LLM for movie recommendations
OP wrote a python script that call a llm to ask for a recommendation.
But you are right, op doesn’t say that everyone shall do it
No, it also doesn’t do that. It gets embeddings from an LLM and uses that to rank candidates.
Are you a trollm?
If not, I’m just too stupid to understand op.
If that’s not the same, I don’t know what is. Gotta go back to school, I guess.
It’s not, I read the code. It’s not merely asking the LLM for recommendations, it’s using embeddings to compute scores based on similarities.
It’s a lot closer to a more traditional natural language processing than to how my dad would use GPT to discuss philosophy.
I love how you actually did something instead of jumping on the generalization train. I hate that about Lemmy right now.
I had to look up embeddings: so this is comparing the encoding of movies as a similarity test?
Which can work because the encoding methods can indicate closeness of meaning.
And that’s why this isn’t running an llm in any way.
LLMs are not the tool for a recommender job
Seriously; local AI use is what everyone should strive for not only for privacy but because it’s better than using a large data centre and the power use for Ollama is negligible.
How does this compare to an ML approach?
are you training or just using an LLM for this?
There’s no training, the LLM embeddings are used to compare the plots via a cosine similarity, then a simple weighted score with other data sources is used to rank the candidates. There’s no training, evaluation, or ground-truth, it’s just a simple tool to start using.
that’s pretty cool, this is just the wrong crowd, don’t worry about the downvotes
thanks ! ^^
Screw AI.
Y’all need LLMs to tell you what to watch, now?
Is it any different that getting movies based on recommendations from employees at video stores?
Yes, LLMs are different from human beings, what kind of question is this?
When you go to a shelf of recommendations, you’re not picking from a human; you’re picking from a shelf.
Ah, yes, those magic recommendations shelves that assemble themselves with no input from human hands or minds. I’d forgotten about those.
A bugs life from mickey 17?
Explain OP
Bugs, obviously.
I remember building something vaguely related in a university course on AI before ChatGPT was released and the whole LLM thing hadn’t taken off.
The user had the option to enter a couple movies (so long as they were present in the weird semantic database thing our professor told us to use) and we calculated a similarity matrix between them and all other movies in the database based on their tags and by putting the description through a natural language processing pipeline.
The result was the user getting a couple surprisingly accurate recommendations.
Considering we had to calculate this similarity score for every movie in the database it was obviously not very efficient but I wonder how it would scale up against current LLM models, both in terms of accuracy and energy efficiency.
One issue, if you want to call it that, is that our approach was deterministic. Enter the same movies, get the same results. I don’t think an LLM is as predictable for that
Maybe lowering the temperature will help with this?
Besides, a tinge of randomness could even be considered a fun feature.
I’m not an expert, but LLMs should still be deterministic. If you run the model with 0 creativity (or whatever the randomness setting is called) and provide exactly the same input, it should provide the same output. That’s not how it’s usually configured, but it should be possible. Now, if you change the input at all (change order of movies, misspell a title, etc) then the output can change in an unpredictable way
Yes. I think determinism a misunderstood concept. In computing, it means exact same input leads to always the same output. Could be a correct result or entirely wrong, though. As long as it stays the same, it’s deterministic. There’s some benefit in introducing randomness to AI. But it can be run in an entirely deterministic way as well. Just depends on the settings. (It’s called “temperature”.)
Did you build it, though, or did Claude code it?
Built with Claude by the looks of things. Not sure if Claude was used to generate the boilerplate and whether the dev reviewed it after or whether Claude did all of it, but definitely Claude was used for some of it. I recognise the coding style that Claude outputs and the bugs that it implements that will cause TypeErrors if not handled.
FWIW, I’m not against using AI as an assistant for coding (I do it too, using Claude and Vercel as assistants) just as long as the code is reviewed and understood in full by the dev before publishing.
A very sane take. I do wish devs would fully disclose this on their github or other. That way, if the project is seasoned, well starred, et al, and the dev used AI as an assistant, then the user gets to decide. Given all the criteria are met, I would deploy it.
I will say that I have observed what seems like a pretty decent up tick in selfhosted apps, and I would be willing to bet a goodly amount of them have at the very least, used AI in some capacity, if not most/all code. I don’t have any solid evidence to back that up but it just seems that way to me.
Yeah. Maybe it’s time to adopt some new rule in the selfhosted community. Mandating disclosure. Because we got several AI coded projects in the last few days or weeks.
I just want some say in what I install on my computer. And not be fooled by someone into using their software.
I mean I know why people deliberately hide it, and say “I built …” when they didn’t. Because otherwise there’s an immediate shitstorm coming in. But deceiving people about the nature of the projects isn’t a proper solution either. And it doesn’t align well with the traditional core values of Free Software. I think a lot of value is lost if honesty (and transparency) isn’t held up anymore within our community.
Warning, anecdote:
I was unexpectedly stuck in Asia for the last month (because of the impact of the war), turning an in-person dev conference I was organising into an “in-person except for me” one at a few days notice.
I needed a simple countdown timer/agenda display I could mix into the video with OBS; a simple requirement, so I tried a few from the standard package repos (
apt, snap store, that kind of thing.)None of them worked the way I wanted or at all - one of them written in Python installed about 100 goddamned dependencies (because, Python,) and then crashed because, well, Python.
So I gave up and asked my local hosted LLM model to write it for me in Rust. In less than 10 minutes I had exactly what I wanted, in a few hundred lines of Rust. And yeah, I did tidy it up and publish it to the snap store as well, because it’s neat and it might help someone else.
Which is more secure? The couple of hundred lines of Rust written by my LLM, or the Python or node.js app that the developer pinky-promises was written entirely by human hand, and which downloads half the Internet as dependencies that I absolutely am not going to spend time auditing just to display a goddamned countdown clock in a terminal window?
The solution to managing untrusted code isn’t asking developers for self-declared purity test results. It’s sandboxing, containers, static analysis… All the stuff that you are doing already with all the code/apps you download if you’re actually concerned. You are doing those things, right?
Good comment. The main issue is this: Back in the day I could have a quick look at the code and tell within a minute whether something was coded by a 12 year old or by some experienced programmer. Whether someone put in so much effort, I could be pretty sure they’re gonna maintain the project. Put in some love because it solves some use-case in their life and it’s going to do the same for me. Assess their skill-level in languages I’m fluent in.
These days not so much. All code quality looks pretty much the same. Could be utter garbage. Could be good software, could be maintained. Could be anything, Claude always makes it look good on a first glance. There’s also new ulterior motives why software exists. And it takes me a good amount of time and detective work to find out. And I often can’t rely on other people either, because they’re either enraged or bots and the entire arguments are full of falsehoods.
As a programmer and avid Linux user, I rely a lot on other people’s software. And the Free Software community indeed used to be super reliable. I could take libraries for my software projects. Could install everything from the Debian repo and I never had any issues. It’s mostly rock solid. There were never any nefarious things going on.
And now we added deceit to the mix. Try to keep the true nature of projects a secret. And i think that’s super unhealthy. I had a lot of trust in my supply chain. And now I’m gonna need to put in a lot of effort to keep it that way. And not fall prey to some shiny new thing which might be full of bugs and annoyances and security vulnerabilities, and gone by tomorrow once someone stops their OpenClaw… Yet the project looks like some reliable software.
And I don’t share the opinion on sandboxing. Linux doesn’t have sandboxing (on the Desktop). That’s a MacOS thing (and Android and iOS). All we have is Flatpak. But you’re forcing me to install 10GB of runtimes. Pass on the distro maintainers who always had a second pair of eyes on what software does, if it had tracking or weird things in it, whether it had security vulnerabilities in the supply chain. Maintainers who also provided a coherent desktop experience to me. And now I’m gonna pull software from random people/upstreams on the internet, and trust them? Really? Isn’t that just worse in any aspect?
And wasn’t there some line in devops? Why is it now every operators job to do static analysis on the millions of moving parts on their servers… Isn’t that a development job?
And I don’t think Flatpak’s permission system is even fine-granular enough. Plus how does it even help in many cases? If I want to use a password manager, it obviously needs access to my passwords. I can’t sandbox that away. So if the developers decide to steal them, there’s no sandboxing stopping them in any way. Same for all the files on my Nextcloud. So I don’t see how sandboxing is gonna help with any of that.
I just don’t think it’s a good argument. I mean if you have a solution on how sandboxing helps with these things, feel free to teach me. I don’t see a way around trust and honesty as the basic building blocks. And then sandboxing/containerization etc on top to help with some specific (limited) attack vectors.
I mean, don’t get me wrong here. I’m not saying we need to ban AI in software development. I’m also not saying 12 year olds aren’t allowed to code. I did. And some kids do great things. That in itself isn’t any issue.
Tho I chafe against rules and regulations, I realize they are necessary.
Me too. It’s why I try to carefully pick seasoned projects, and I don’t jump on the bandwagon just because it’s a new twist to an old solution. I selfishly want others to be my beta testers. LOL Hey, I admit it. Also, I am truly thankful that there exists in the community, those who can and do look at the code and understand the issues involved. I do not possess those skills. I know a limited amount of code and use it for me locally. I would never dare publish it tho. I’m too afraid of what the ramifications would be should someone use my code and the wheels fall off their server. I would feel very responsible. It’s the reason I do not even publish my notes to a wiki of some sort.
I think the problem is a cyclical one. Some devs are afraid to admit that they used AI to help them code because there’s so much hatred towards using AI to code. But the hatred only grows because some devs are not disclosing that they’ve had help from AI to code and it seems like they’re hiding something which then builds distrust. And of course, that’s not helped by the influx of slop too where an AI has been used and the code has not been reviewed and understood before its released.
I don’t mind more foss projects, even if they’re vibe coded, but please PLEASE understand your code IN FULL before releasing it, if at least so you can help troubleshoot the bugs people experience when they happen!
I would say there is a lot of truth to that statement. The backlash is immediate and punishing. I’ve said before, I think there are a lot of young devs who would like to contribute to the opensource/selfhosting community, but lack the experience.
We also have issues with young people in the industry. As some junior developer stuff is now done by AI, we’re lacking more and more positions to start in, and learn the ropes. And you can’t start out as a senior, either. So that got more complicated as well.
Experience is something you never have until after you need it.
Cowards. “Some devs” would not survive five minutes in the real world as a queer person.
Honestly, any developer that isn’t using an LLM as an assistant these days is an idiot and should be fired/shunned as such; it’s got all the rational sense of “I refuse to use compilers and I hand-write my assembly code in
vi.”(And I speak as someone who has a
.emacsfile that’s older than most programmers alive today and finally admitted I should stop usingcshas my default shell this year.)Here’s the disclosure you need: all projects you see have involved AI somewhere, whether the developers like to admit it or not. End of. The genie is out of the bottle, and it’s not going back in. Railing against it really isn’t going to change anything.
I’ve said it before, AI is here to stay. It’s not a fad. Kind of like when the internet first started to become publicly available. Lots of people deemed it a fad. It’s now a global phenom and it is the basis by which we do business on the daily, minute by minute, globally. I do think that AI needs some heavy governmental regulation. It would be great if we could all play nicely together without involving the government(s). Alas, we don’t seem to be able to do that, and so, government(s) has to step in, unfortunately. The problem with that is, imho, surveillance capitalism has worked so well that governments also want to take a peek at that data too. I have nothing to back up that conspiracy theory, it’s just a feeling I get.
Haha. I think there’s often a rough idea on what kind of programmer people are, judging by their opinion on these AI tools.
Have you tried arguing with your AI assistant for 2.5h straight about memory allocation, and why it can’t just take some example code from some documentation? And it keeps doing memory allocation wrong? Scold it over and over again to use linear algebra instead of trigonometric functions which won’t cut it? Have you tried connecting Claude Code to your oscilloscope and soldering iron to see what kind of mess its code produces?
I’m fairly sure there are reasons to use AI in software development. And there are also good reasons to do without AI, just use your brain and be done with it in one or two hours instead of wasting half a workday arguing and then still ending up doing it yourself 😅
I don’t think these programmers are idiots. There’s a lot of nuance to it. And it’s not easy at all to apply AI correctly so it ends up saving you time.
I mean, I haven’t argued with an AI for 2.5 hours straight, because I know how to use them. And I don’t expect them to think for me, because I know they’re not capable of it.
I was writing assembly language for embedded controllers where the memory is measured in bytes not megabytes, professionally, before half of you were born. I’ve developed preemptive multitasking OSes for 8 but microcontrollers, by hand, for money. These skills ceased to be particularly useful decades ago, but I didn’t sit down and sulk because optimising compilers and ludicrously cheap memory had ended my career, I moved with the times.
Practically everyone who calls themselves a “programmer” has never had the training wheels taken off since the invention of managed runtimes, you don’t now get to complain about what is or is not proper programming. The actual software engineers, who understood that the code was always just a side effect of their real job - understanding and solving problems - just have a new, and really cool, tool to learn how to use. The ones who aren’t up to it will spend 2.5hrs arguing with their AI, and then go back to coding for a hobby. And that’s fine - but if you refuse to learn AI as a tool, you no longer have a career in this industry. Any more than I would’ve if I had refused to accept that memory is basically free now and compilers can write assembly better than me.
I don’t have a definite answer to it. Could be the case I’m somehow intelligent enough to remember all the quirks of C and C++. Eat a book on my favorite microcontroller in 3 days and remember details about the peripherals and processor. But somehow I’m too stupid to figure out how AI works. I can’t rule it out. At least I’ve tried.
I still think microcontroller programming is way more fun than coding some big Node.JS application with a bazillion of dependencies.
And I sometimes wish people would write an instant messenger like we have 4MB of RAM available and not eat up 1GB with their Electron app, which then also gets flagged by the maintainers for using some components that have open vulnerabilities, twice a year.
I mean I don’t see any reason why I shouldn’t be allowed to complain about it.
But yeah, software development is always changing. And sometimes I wonder if things are for the better or the worse.
I’ve had a lot of bad experience with embedded stuff and trying to let AI do it for me. I mostly ended up wasting time. I always thought it must be because these LLMs are mainly trained on regular computer code, without these constraints and that’s why they always smuggle in silly mistakes. And while fixing one thing, they break a different thing. But could also be my stupidity.
I’ve had a way better time letting it do webfrontends, CSS, JavaScript… even architecture.
But I don’t think this (specifically) is one of the big issues with AI anyway. People are free to learn whatever they want. There’s a lot if niches in computer science. And diversity is a good thing.
Lol. For someone who says they expect other people to learn something, you’re a bit short in supply. I mean this would be an opportunity for someone (me) to learn something. But a down-vote won’t do it. And lessons on what not to do (discuss 2.5h, expect it to think) don’t lead anywhere either. I’d need to know what to do in my situation. Or where to find such information?!
Or was it because I said I value efficiency and for some reason you’re team bloat? I seriously don’t get it.
This is a cool tool. Thanks for sharing. Don’t worry about the downvotes. The Fediverse has a few anti-AI zealots who love to brigade.
Thank you ! :)
The more local inference, the better. Nice work!
thanks for your kind comment :)
Anti-AI evangelism is at its peak rn.
@pfr @nikodindon That assumes it won't get worse, which I hope it does. AI companies have forced me to take down web stuff that I had running for almost 2 decades, because their scrapers are so aggressive.
Like what and what have you tried to block it?
@meldrik They're impossible to block based on IP ranges alone. It's why all the FOSS git forges and bug trackers have started using stuff like anubis. But yes, I initially tried to block them (this was before anubis existed).
It was a few things that I had to take down; a gitweb instance with some of my own repos, for example. And a personal photo gallery. The scrapers would do pathological things like running repeated search queries for random email addresses or strings.
I’m hosting several things, including Lemmy and PeerTube. I haven’t really been aware of any scrapers, but do you know of any software that can help block it?
Found the time traveler!
ai;dr
Sorry OP that you’re getting downvote bombed. This is actually really neat. People go nuts when they hear AI but this is fully local so I think this reaction is unjust. This has nothing to do with ram prices since that stems from data centers or corpos pushing AI on you. Thank you for sharing
thanks for your comment :) I edited my original post to explain the project better
Thanks for the discussion ! I Added more details on the various modes. Apparently I sparked some controversy , I understand some people don’t like AI. I find the tool pretty cool to use, feel free to test it and report anything you want ^^